A few years ago, I started experimenting with a new approach to evolving CSL in GitHub - bdarcus/csln: Reimagining CSL .
But I’m busy, and am amateur programmer with aspirations that (far) exceed my time or skills.
In the past week, however, I’ve been doing a deep dive into new agentic coding tools; notably using the latest Claude’s Opus and Google Gemini models.
After I got more comfortable with how to exploit these tools, I threw this new project together in less than 24 hours, and I have to say: I am super impressed. It already does much more than what I achieved with the earlier project (though is borrowing code from it).
I should add, however, a huge question for me remains whether the 100% fidelity claim mentioned in the README is even possible. I aim to figure this out over the coming weeks (though early progress is slow, so it may take many weeks!)!
Basically, I had these tools analyze how to extend my earlier experiments (which got pretty far actually) in order to bring the vision to completion.
Perhaps the most interesting possibility this opens up, I think, is reflected in the contributing section of the README, which you can see if you create a new issue and select “domain expert.”
The prior art analysis is also super interesting. It’s the result of me asking how to synthesize all the information in the respective code bases, the csln repo issue tracker, and in the spec documents for CSL/M 1.0. That’s now incorporated in to the roadmap (this file, while human readable, is aimed at the LLM tools).
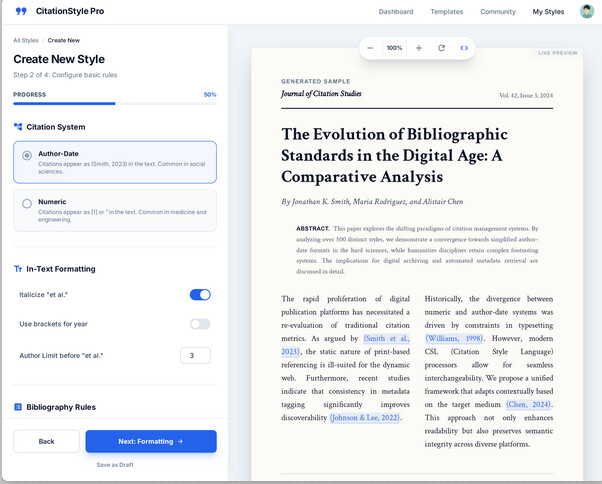
Here’s a parallel project with the start of a rust-based server, upon which I intend to build a client UI based on an idea I’ve previously talked about, that I will make sure the core code supports (for live-previewing and such). Here’s the browsing UI I imagine:

And this is a representation of the creation wizard I’ve previously discussed, with the idea being it has live previewing.