Style updates with every release is fine, yes. Also makes style versions easy to track if necessary for support. Thanks.
1 Like
A CDN usually involves:
- Uploading files to an S3 bucket (the “origin”) or similar in a CI step on the styles (and locales) repos
- Configuring a CDN to point to
"https://my-bucket.s3.amazonaws.com/"+ the rest of the path. - The rest is getting the caching right. It’s harder than it looks, and feeds pretty directly into how long people will wait before seeing new versions. You don’t want the answer to be “forever”. Defined by:
- The origin’s cache headers
- How the CDN edge nodes will cache results from the origin
- How clients will cache results from the edge nodes
Would we qualify for CloudFlare’s free pro upgrade for “not-for-profit + provide engineering tools or resources to the developer community” organisations? Maybe by a hair? In any case, CloudFlare has an unlimited free CDN that would probably be fine. AWS also doles out one-time $2000 credit to nonprofits.
Caching for a registry like the one I described earlier is better than caching for 24 hours or whatever duration. This is 100% because each updated version has a new name when you factor in the version number. So a file can never be out of date. For example, Rust’s Cargo package manager downloads from https://crates.io/api/v1/crates/serde/1.0.89/download, which is a 302 Found redirect to https://static.crates.io/crates/serde/serde-1.0.89.crate. If you want it again, it’s in a cache directory or on an edge node essentially forever or until you clean up disk space. When you want 1.0.90, you get the one and only 1.0.90 from an edge node, and keep that.
CSL styles, however, don’t have version numbers so you’d be requesting the same file with the same name. (@Sebastian_Karcher that does make your ‘make style versions easy to track’ a little difficult.) Basically we don’t want that same filename to mean the edge nodes cache the first origin response forever, but we don’t want to make the CDN a cache-less proxy.
So there are three ways of busting this:
- Literally don’t use a CDN. Just use S3. More requests; costs more to run.
- Do invalidations of all changed files at all edge nodes. These can cost extra because they are hard to pull off for providers. I know they do on CloudFront. Can be a bit iffy. Not sure if CloudFlare has an API for it.
- Create a
registry.json. The analogue to the crates.io index e.g. for roxmltree or to NPM, but in one file.- Produced from the repository on each push with a ‘moving target’ for each style, like a version but not quite. A ‘most recently updated in XXX git commit’ or ‘sha1 of file contents’ would work fine. As long as it changes when the style changes.
- Add, for example, an optional but recommended query string to style and locale requests:
?v=XXX. Make these distinct in the cache. - Cached differently from the rest. I.e. turn off caching for
/registry.jsononly and rely on 304 Not Modified and ETags. Everything else can be cached forever as it is version-addressed. - Ideally forwards-compatible in case we wanted to make things modular and version-based.
Example registry.json below with a sketch of how dependent styles might work. You could include other metadata e.g. default locales to make other fetching tasks/optimisations easier. Maybe also human-readable names so that registry.json can power a search/list viewer, but that’s inflating the size a little. Forwards-compatibility is through assembling this file differently later on (e.g. with an API) and setting up a different origin for that file. More ideas over at crates.
{
"download": "https://registry.citationstyles.org/styles/",
"locales": { },
"styles": {
"apa": { "version": "0f9b6e915dd01f25e0e0efb3fe8e585f22fb3aa0", "parent": null },
"some-dependent-style": { "version": "...", "parent": "apa" }
...
}
}
Then your basic fetch function:
let registry = await fetch('https://registry.citationstyles.org/registry.json').then(r => r.json());
let fetchStyle = async (sty) => {
let dl = registry.download;
let { vers, parent } = registry.styles[sty];
if (parent) { /* ... fetch that too ... */ }
let url = `${dl}${sty}?v=${vers}`;
return await fetch(url, { 'Content-Type': 'application/xml' }).then(r => r.body());
};
I guess that’s just a sketch but it should give you an idea of the complexity.
The end result would be that you can have:
- a button to refresh the registry so users can make sure they have the latest styles in their app without worrying about any particular style. Simple instructions to users, too. “Check for style updates.”
- updates reflected nearly-immediately in the wild
- you can pretty easily tell your users if there’s a new version of their preferred style (“would you like to update?” + link to github history for the file)
- obvious implementation for new languages etc. The code for a standard write-through cache is idiot-proof. In a browser you’re pretty much done with the above. CLIs and desktop apps can do their own uncomplicated cache even if their HTTP library of choice doesn’t already do it:
- cache registry.json but fetch it periodically (flag to force etc, short timeout because not urgent)
- store everything else by
name/versionforever, in SQLite or the filesystem.
Some numbers: using sha1 hashes, registry.json is 204kB, or 76KB gzipped. Pretty big really, but ETag it well and it should be fine with lots of 304s. Better than 20MB. This is the file you use invalidation/purging for if at all, which means the edge nodes can keep it.
Here is my proof of concept: https://github.com/johanneswilm/citeproc-plus I have refactored the standard citeproc-js demo to use this instead.
The demo is a webpage bundled with webpack. The citeproc-plus package is bundedled with rollup. The point is to show that it’s possible to create a citeproc bundle inclusing the localization and style assets which then can be imported in another project (the demo site) using a different bundler. It takes split seconds to rebuild the bundle on the webpage. The download size of the citeproc-plus main bundle is somewhere around 756kb, which is slightly too large, and it could probably be optimized. But it’s not really way too large either.
I’m looking forward to constructive criticism. Unless someone can tell me that there is something fundamentally wrong with this, I think this is the kind of setup we’ll want to migrate to with Fidus Writer so that we can provide all the styles and don’t have to worry about the database, etc. .
For comparison: citeproc-js takes up 896kb unbundled and around 746kb in the final webpack bundle. Overall the size is not increasing by a lot. The list of style names and urls would be the only thing that is added.
I also tried using dynamic imports to better compare [1]. That was not possible as rollup failed with an allocation failure.
[1] https://github.com/johanneswilm/citeproc-plus/tree/dynamic-import
I’ve made another few changes and improved the readme of citeproc-plus. It’s now at the point where I think it’s feature complete for everything we need in Fidus Writer and not just a proof of concept. I didn’t include dependent styles yet, but if I have understood the concept of “dependent style” is basically the same as an alias, right? So it would be enough create a third export, for example styleAliasOptions with all the dependent styles and just letting those link directly to the independent style files, right? If so, I could do that eventually or maybe someone else whop needs this is interested in adding it?
To make it really clear: I have no intention of stepping on anyone’s turf. I asked previously what naming preference there would be here, and since there was no feedback on that point, I picked citeproc-plus as the temporary name for the proof of concept. On the one hand, using citeproc in the name may make some people think that it’s an official package from you guys. On the other hand, not mentioning it would be unfair to you guys who in reality wrote 99.9% of what is contained in that package. I’m very happy to change that though to accommodate your preferred naming policy.
I am also willing to give up maintainership of the package entirely to someone here who is following the development of citeproc and CSL more closely as long as the current features will be preserved in some form (because that’s the stuff we happen to need).
Over the years, people have self-adopted the “citeproc-<programming-language>” naming schedule for CSL processors in different languages. See Developers - Citation Style Language for a list (“citeproc-java” is technically a wrapper of citeproc-js, but otherwise things are pretty consistent). Note that the CSL core project doesn’t have any official CSL processors. They’re all independent, although @Frank_Bennett’s citeproc-js is usually used as the reference implementation.
So something like “citeproc-js-plus” would already be clearer, plus a note that it’s an unofficial bundle of citeproc-js. I’ll defer to Frank on this, though.
1 Like
Thanks for clarifying @Rintze_Zelle ! I wasn’t thinking outside of npmjs, but you are right that there is a point in saying what language it is if it is going to be listed anywhere else. @Frank_Bennett would you also be ok with citeproc-js-plus and do you have a preference of a sentence that clarifies that it’s an unofficial build? And where would you want me to put that sentence?
It actually looks like the “-js” part of the name is skipped on npm. So maybe call it citeproc-plus-js or citeproc-js-plus outside of npm and citeproc-plus on npm?
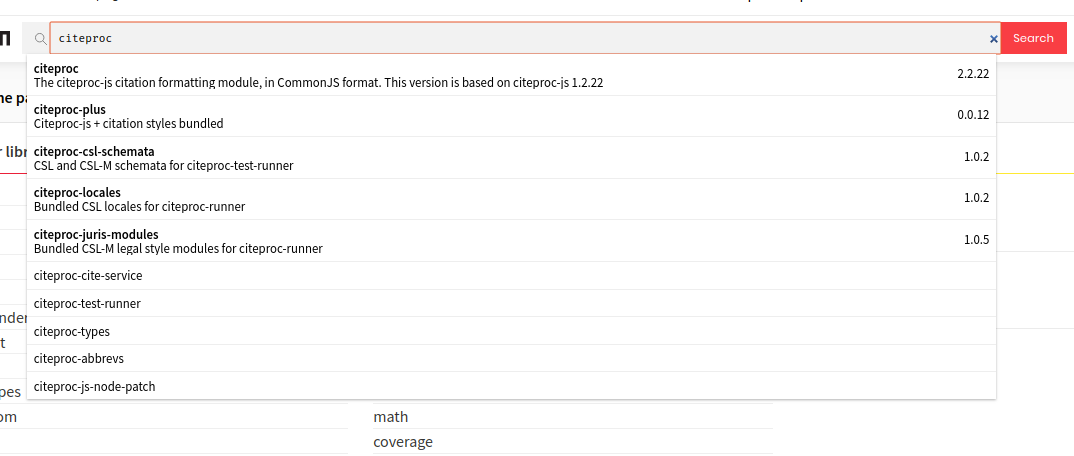
A bunch of the names that turn up in that SAYT listing are under my control, and I’ve been meaning to enter the discussion after the naming issue was settled. Time to come clean.
-
citeprocis a project that I took over long ago, as part of a clean-up ofciteproc-js-related packages innpm. -
The packages
citeproc-locales,citeproc-juris-modules, andciteproc-abbrevsare dependencies ofciteproc-cite-service, which performs a server-side read-only sync over the Zotero API, for use in maintaining an arbitrary website with Zotero content. -
citeproc-csl-schematais a dependency ofciteproc-test-runner.
I could deprecate all of these, and rename them to something like citeprocjs-*, if that is desired. Most would probably affect only one project at this point. I suspect that the citeproc package is a dependency to quite a few projects out there, so renaming that one would likely trigger quite a few update warnings across the ecosystem.
An alternative (which I’ll suggest because I’m lazy, and likely to be shouted at in any case) would be to leave the names as they are, but be clear in the project description that a package is specific to citeproc-js.
I wouldn’t worry about those names at all. citeproc-plus is fine as well, although I would recommend using peerDependencies for the citeproc dep so you don’t have to cut a new release every time Frank does. You can’t unpublish any of them now, and deprecated packages still show up in searches for ages so changing is very noisy without much benefit. If you were going to change names, you would 100% be using an NPM scope (@citeproc-js/*) to group officially related projects together.
FWIW, I was planning to use citeproc-wasm on NPM. I guess citeproc-rs would also be fine. Maybe use the @citeproc-rs/*scope and also publish JS-land code with higher level APIs like the js-demo code has in the repo today.
The reason I cannot do that is that the citeproc-plus build script “castrates” the citeproc package (removes the ability to process XML and instead uses that space on the list of styles) and then eats it up so that there is only one ES2018 and one CJS JS export file. The citeproc package therefore is only a build dependency, not a runtime dependency.
As you had mentioned earlier that there can also be daily style updates, I was thinking maybe there is some smart if-then setup out there that can be set to automatically release a new version of one package when another package has been released. Alternatively it should be possible to set up a daily cronjob that just checks whether one of the three dependencies (citeproc-js, styles or locales) have had an update and if so make a build and release a new patch version to NPM. Surely we are not the first ones coming across that issue, so I assume there must be something out there to handle such a situation.
Ok, so maybe the best is just to follow the advice of @Frank_Bennett and make sure it says citeproc-js fairly high up in the description text? And then if there is some general effort here to move all the packages to a scope some day also to move this along with everything else. Sounds good? Any idea of what kind of wording there should be to make clear that it’s an “unofficial” package?
Maybe something like:
citeproc-plusincorporates styles and locale files from the Citation Style Language project, as well asciteproc-js, the JavaScript CSL processor library by Frank Bennett.
1 Like
Every CI ever can do a cron job. There are hundreds. GitHub Actions is in beta, seems fun, but you’d do fine with Travis if you’re not on the waitlist already. Could also use dependabot or similar in auto-merge mode for the citeproc dependency, and get your CI to auto release on master so the merged PRs cause a release. And you’ll have to make it commit the bumped version and push that back to GitHub. Maybe someone has written a GitHub action for that specific thing.
I’d still recommend not cutting up citeproc-js using text replacement + making everything a bit more complicated to save maybe a few kB in the context of hundreds? But the above should work fine and this particular solution inherently involves a stream of noisy releases, so not much you can do about that now.
Ok, I’ve put this sentence quite high in the readme:
citeproc-plusincorporates 2000+ styles and 50+ locale files from the Citation Style Language project, as well as citeproc-js, the JavaScript CSL processor library by Frank Bennett.
Looks good? By adding the numbers I didn’t have to state the same things again in the next sentence. The numbers explain for those not familiar with the issue why this is an issue at all. If there were say 5 different styles altogether worldwide they would probably come bundled with citeproc-js anyway.
I had hoped to save even more in the long run. I can see there are some smaller functions that aren’t referenced anywhere (such as CSL.stripXmlProcessingInstruction) and hopefully also some larger ones that I haven’t found yet. The problem is that the treeshakers of the bundlers cannot easily find and discard them due to the way citeproc-js is structured. The text replacement then does that it can find some more of them.
Anyway, as you pointed out, the entire structure of it all means that it even without citeproc-js being castrated, there still is the issue of those other two repositories creating updates that should lead to a new version being released. I was also thinking of a CI, but then again that would require the ability to push to the repository and to release to NPM… Likely all doable, but easier if there is a script for that already.
Thanks, will leave those in place.
I was thinking it might be good for us to flag the specific processor in the package.json description, so that folks browsing on npm can have that information before hitting the package README page or installing. Just a thought.
citeproc-js is also mentioned in the description, but not the version number. Should we try to add that? The readme text from github is automatically used by npm as the larger project description, so users should also see the readme before installing. Btw, I noticed that citeproc-js doesn’t have that kind of a readme, which is why the description page on npmjs is kind of empty: https://www.npmjs.com/package/citeproc vs citeproc-plus - npm
There are also no keywords. Maybe we should add a keyword to all citeproc-js related packages “citeproc-js”?
The citeproc package should indeed have a proper README. I’ll try to get one in place soon. Like the idea of tagging also.
The README is there, npm just does not seem to support non-markdown files (I’ve filed a request).